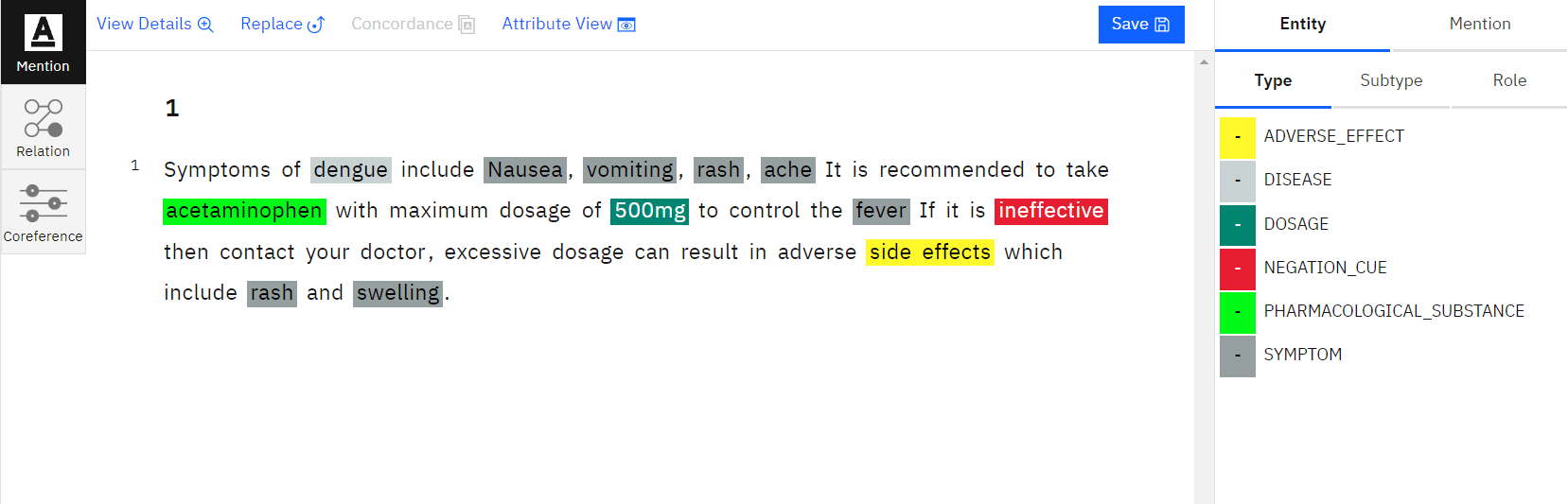
Text annotation makes sentences more intelligible by assisting NLP based machine learning models in identifying key words. In order to effectively train the NLP machine learning algorithm, the texts are annotated with metadata and highlighted by highly skilled annotators, who make sure to carefully read each text.
Named Entity Recognition in NLP
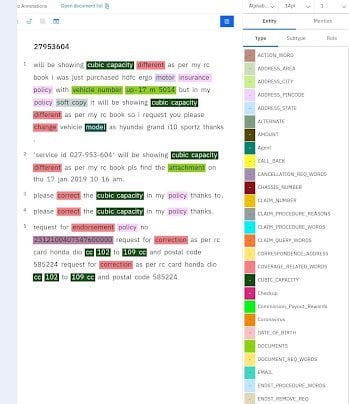
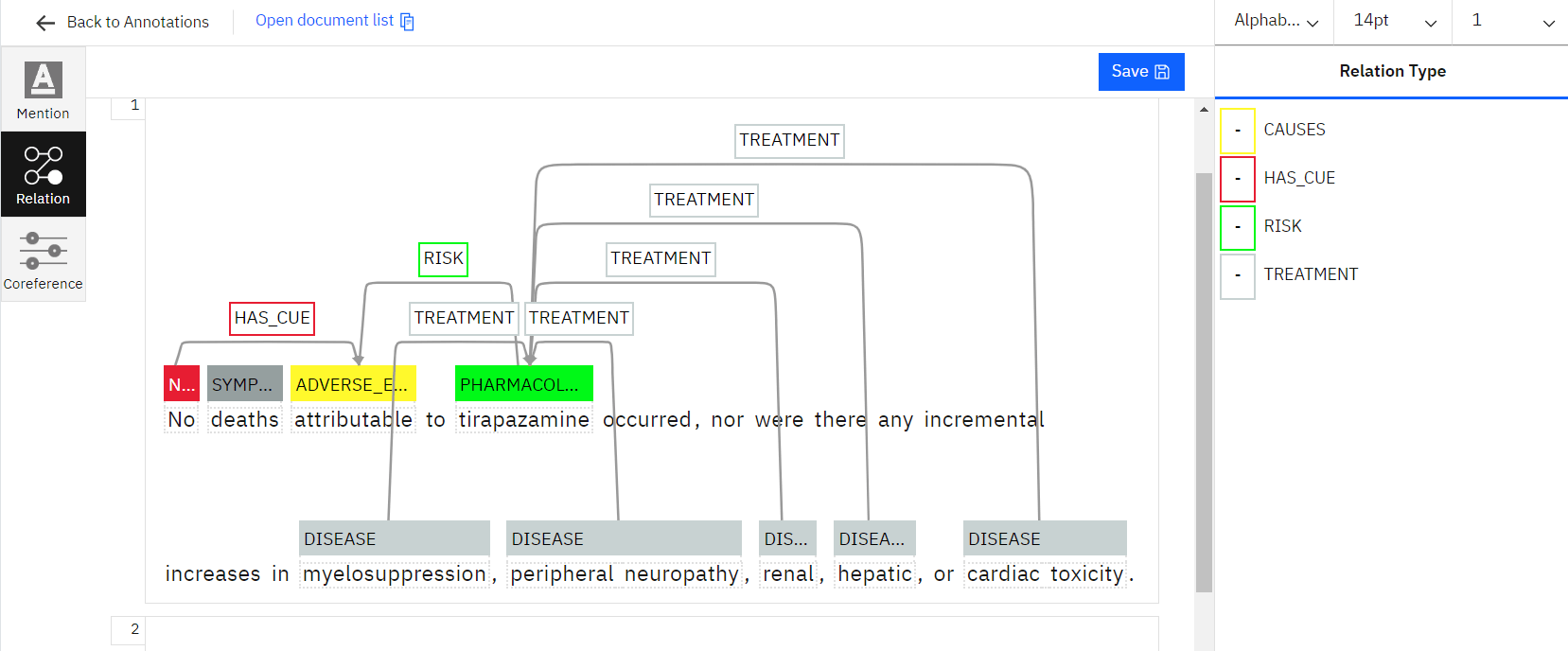
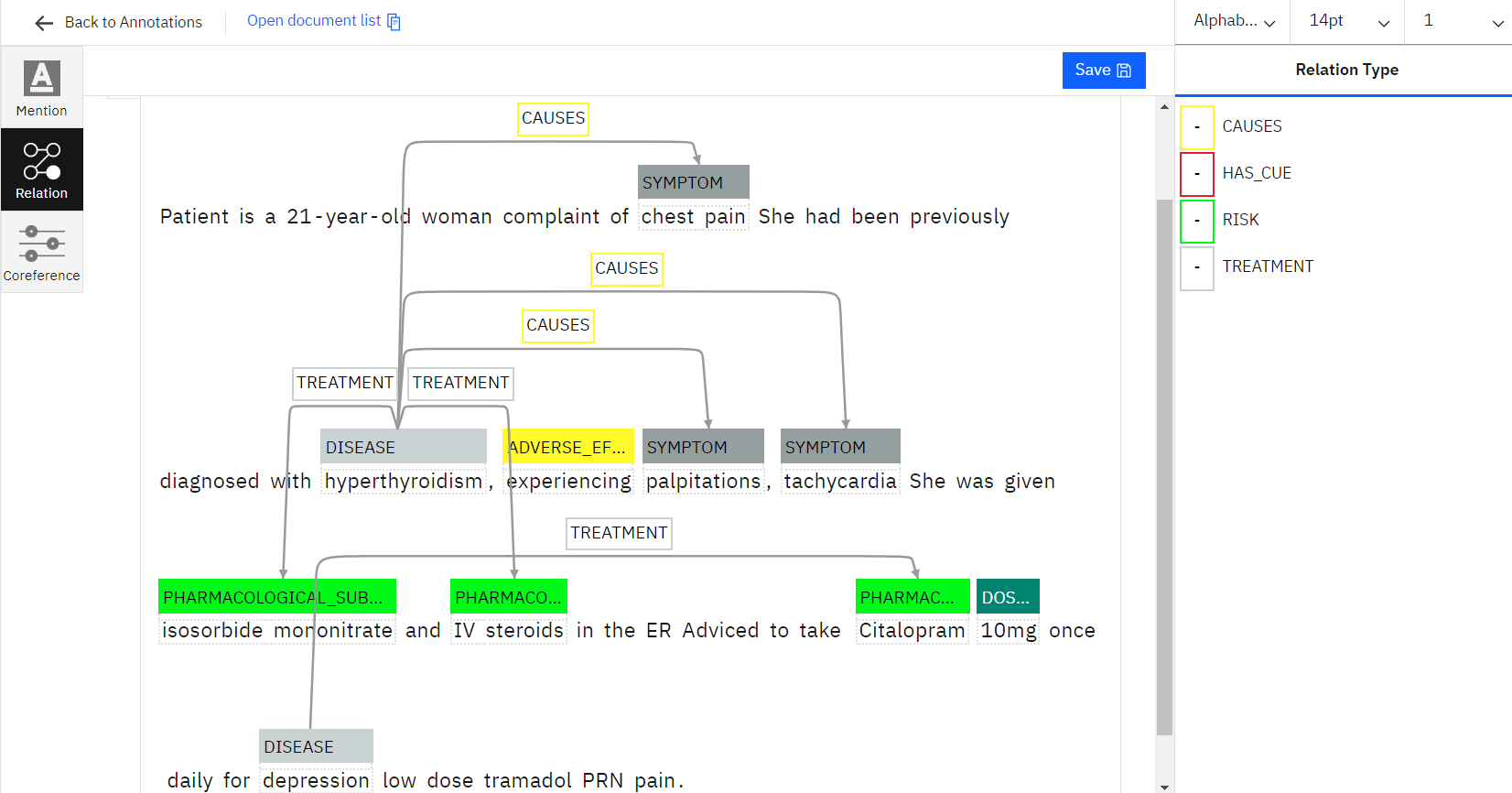
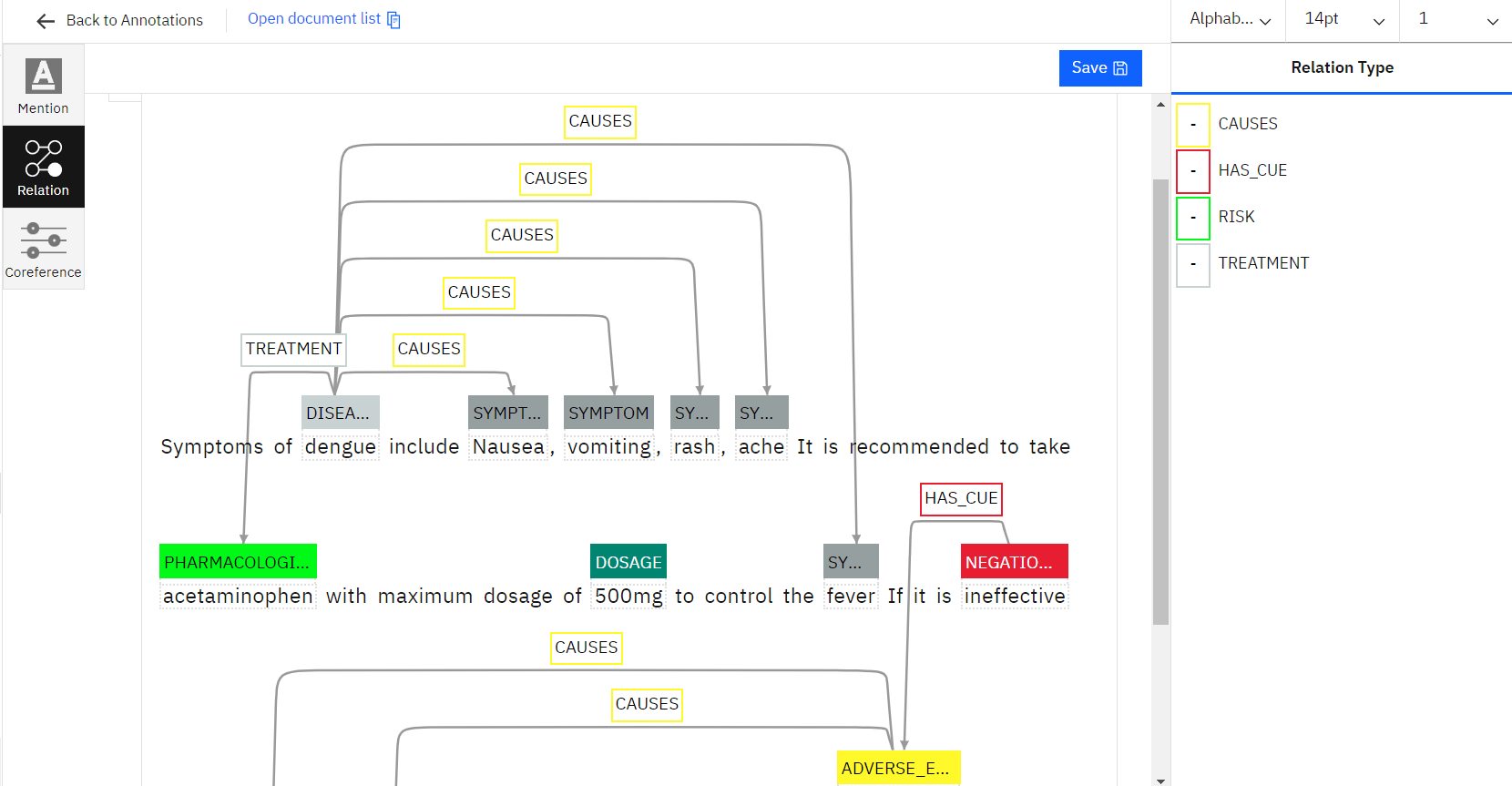
NLP, one of the most crucial techniques to extract pertinent information from the text document, includes named entity recognition. By labelling multiple entities like name, location, time, and organisation, NER annotations assist in the identification of the entity. As a result, NLP named entity recognition is crucial for enabling machines to comprehend the critical text in NLP entity extraction for deep learning.
Entity Relationship Extraction for NLP
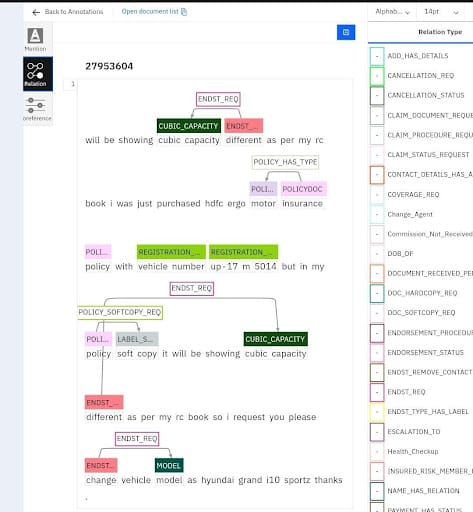
Relation extraction for NLP is done to train artificial intelligence (AI) models based on natural language processing to learn the relations with the various entities in a text to analyse the collected data. Entity extraction can be done using a variety of methods, from straightforward automated approaches to sophisticated string matching. However, the rigorous manual work of our experts can only produce correct results for AI- or ML-based NLP.
Medical Entity Linking
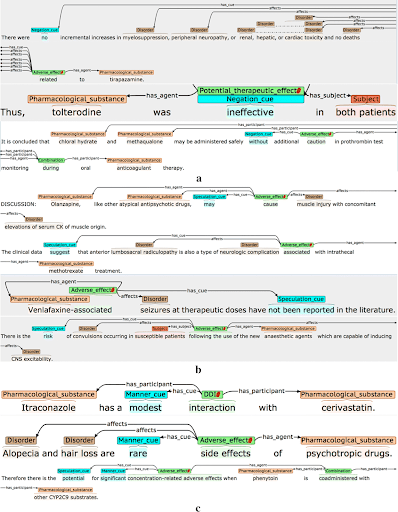
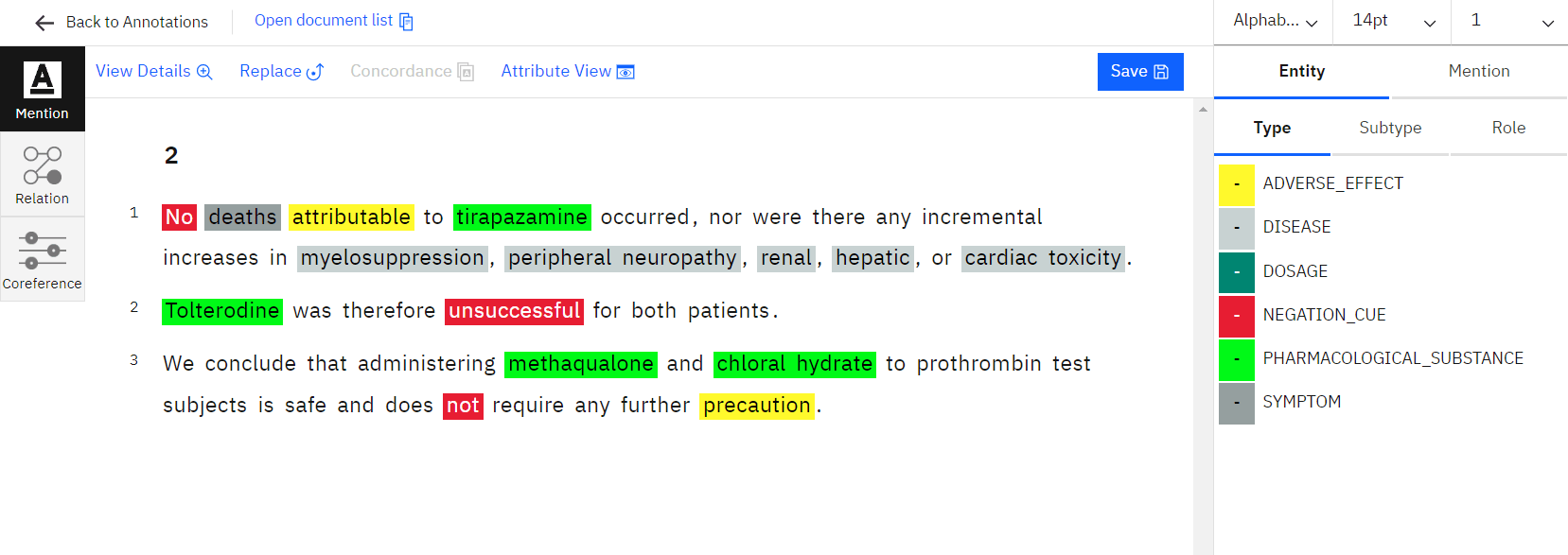
The recommendation of medical therapy is made easier by assisting in establishing linkages between terminology or entities in the patient prescriptions. Machine learning algorithms are built on the foundation of medical prescription labelling to function more effectively and to streamline healthcare facilities without requiring human participation. This plays a critical role in identifying counterfeit prescriptions.
Image Annotation for Machine Learning
With accurate capture techniques, image annotation services can annotate all sizes and types of photographs to make them recognisable to machines or computer vision. In order to provide training data for machine learning in multiple subfields, we are using the best tools and methodologies to annotate images from various domains.
Semantic Segmentation
The elements of the image can be distinguished by humans as distinct things. Semantic segmentation links each pixel of an image with a certain object class in order to teach a computer to perform the same task (e.g., tree, vehicle, human, building, highway, sky). The same-class pixels are then grouped together by the ML model.
In order to train the machine to “see” the individual things on the image, it produces a map with clusters of various object types.
Bounding Box
The bounding box involves drawing a rectangle around a certain object in a given image. The edges of bounding boxes ought to touch the outermost pixels of the labeled object.
3D Cuboids
Similar to the bounding box annotation, the 3D cuboid annotation requires the user to not only create a 2D box around the item but also account for its depth. It can be used to annotate items that need to be grasped by a robot, such as those on flat planes that need to be navigated, such cars or planes.
Polygons
When precise annotations are required for photos with erratic sizes and lengths, such as traffic and aerial photographs, polygon annotation techniques are used. In this technique, a mask is created at a pixel level around the object.
Keypoint Annotation
An Machine Learning algorithm is trained to predict the forms and motion of natural objects by designating the primary (key) points for each one. This process is known as keypoint (also known as landmark) annotation. Keypoint annotation is frequently used for tasks like recognising facial expressions and emotions, following the movements of people and animals.
This website stores cookies on your computer. These cookies are used to improve our website and provide more personalized services to you, both on this website and through other media. To find out more about the cookies we use, see our Privacy policy.